

Get notified as soon as your Grepsr data is ready
When you save a callback URL, Grepsr will automatically invoke a remote script as soon as extraction is complete to send a POST request to the URL with download links to your data as parameters (csv_url, xlsx_url, xml_url, json_url, yaml_url) with the request.
Here’s a brief video demo:

Setup
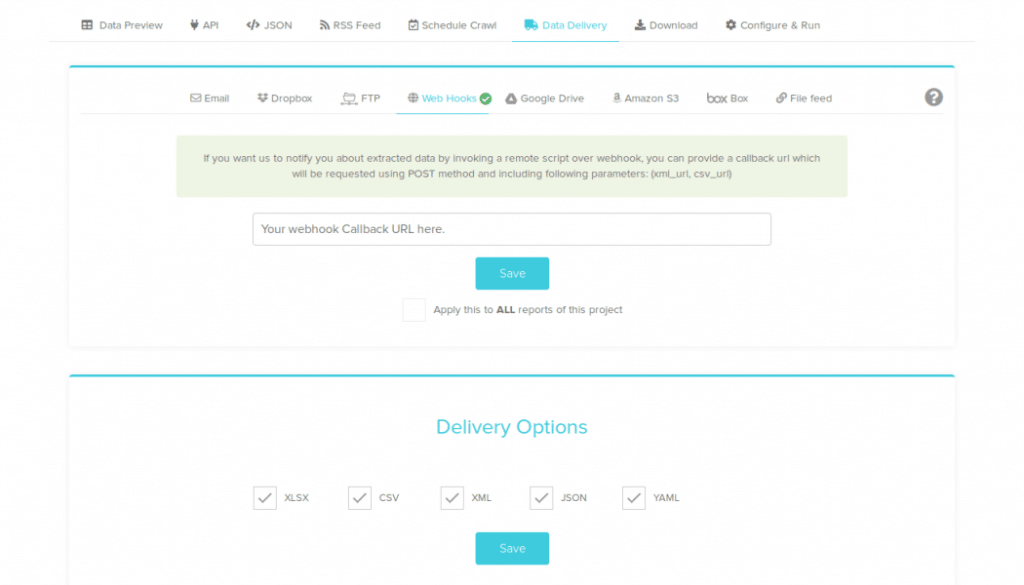
- Head over to your project on the Grepsr app, then Report > Data Delivery > Webhooks.
- On the input field, enter your webhook Callback URL.
- Under Delivery Options, select the applicable file formats, then Save.
Data Delivery
As soon as the crawl is complete and the files are exported in the specified formats, Grepsr sends a POST request to the webhook Callback URL with the download links as parameters.
Delivery Sample via Web Hook
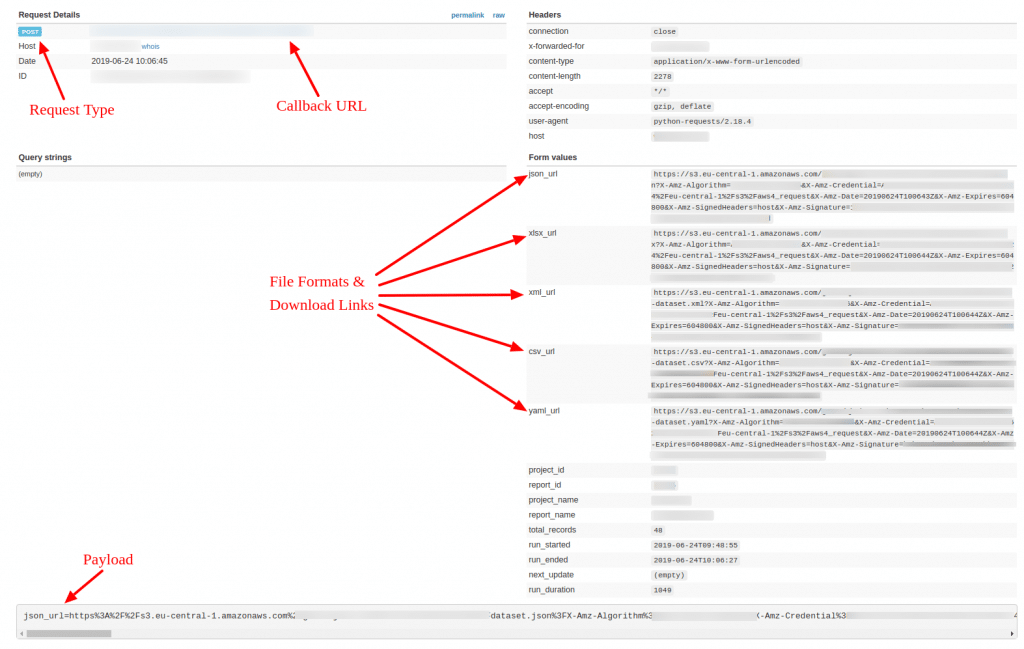
Sample Payload:
json_url=<JSON download URL>&xlsx_url=<XLSX download URL>&xml_url=<XML download URL>&csv_url=<CSV download URL>&yaml_url=<YAML download URL>&project_id=<project ID>&report_id=<report ID>&project_name=<project name>&report_name=<report name>&total_records=48&run_started=2019-06-24T09%3A48%3A55&run_ended=2019-06-24T10%3A06%3A27&next_update=&run_duration=1049
Each of the “_url” parameters gives you the exact storage location of the corresponding file type.
Most of the payload parameters are self-explanatory. The other parameters are explained below:
total_records: The number of records extracted (rows) during the current crawl run.run_started: The timestamp of when the current crawl run started. (Format:YYYY-MM-DDThh:mm:ss)run_ended: The timestamp of when the current crawl run ended. (Format:YYYY-MM-DDThh:mm:ss)next_update: If a schedule is added for the report run, this designates the timestamp of the next crawl run. (Format:YYYY-MM-DDThh:mm:ss)run_duration: The total time taken for the latest crawl run to complete (in seconds).
Note: In case your report has multiple datasheets, the files are saved in a zip package which you’ll need to unzip/extract manually.















































































































































