

Ask anyone what powers ChatGPT, and they’ll probably say ‘AI’ or ‘algorithms’ or something about deep learning. Fair. But what most people miss is the ingredient behind these AI models: data. Mountains of data.
Chatbots answering support queries. Recommendation engines that get you. All of it depends on training data: the right kind, in the correct format, from the right place.
If that data is loose, biased, outdated, or just wrong, AI doesn’t stand a chance. The quality, format, and origin of training data make or break performance of an AI system.
Let’s learn what AI training data actually looks like and discuss what makes data usable. We’ll also talk about Grepsr, the only tool you’d need to get large-scale, error-free data at scale.
Training Data: The Backbone of AI
It’s easy to get caught up in the architecture wars: GPT vs. BERT vs. whatever’s next. But at the end of the day, the AI model is only as good as the data it learns from.
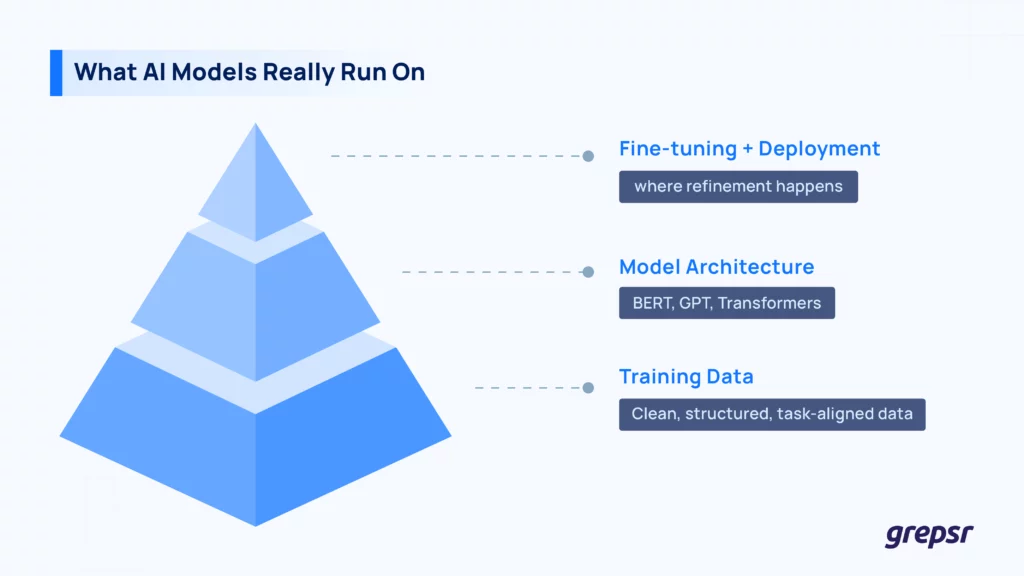
Training data is where AI gets its experience. It’s how a model learns language patterns, image features, user behavior, or any kind of task-specific logic. We humans too work like that; if a person reads a bunch of poorly written books full of misinformation, they’re not going to come out smarter. The same goes for AI.
The model doesn’t just know, it learns
Every weight and parameter in an AI model is adjusted based on the data it sees. That means bias in, bias out. Gaps in data? The model won’t fill them. It’ll just make guesses, and not always good ones.
This is critical when you’re training models for real-world applications: recommendation engines, fraud detection, sentiment analysis, medical imaging, autonomous vehicles. These aren’t sandbox experiments.
If the training data doesn’t reflect the complexity, messiness, and edge cases of the real world, your AI won’t either.
Garbage in, garbage out
Low-quality data leads to overfitting, when the model memorizes noise instead of learning patterns. Or underfitting, when the model doesn’t have enough signal to pick up on anything useful. Either way, you get a model that fails in practice.
On the flip side, proper training data dramatically reduces training time, improves accuracy, and even allows smaller models to outperform bloated ones. Scale is not everything; it’s mostly about signal-to-noise ratio.
| Want high-quality data at scale, just the way you want? Check out Grepsr. Data quality is the primary factor that determines how well your AI model works. With Grepsr, you don’t need to worry about creating your own scrapers, proxies, or getting blocked. Simply let us know what you want (and how), and we’ll give you clean, high-quality data at scale, just how you want it. Happy model training! |
Common Data Formats: What Does AI Eat?

Once you get the data, the next question is: what shape is it in?
AI models are picky; they need structured, well-organized data to learn effectively. Training data falls into a few common formats, each for different use cases:
- CSV (comma-separated values): The go-to for tabular data. Clean, simple, and easy to parse. Used heavily in anything from classification models to regression and clustering.
- JSON (JavaScript object notation): A favorite for hierarchical or nested data, especially for text-heavy or metadata-rich datasets like user reviews, product listings, or API responses.
- Excel (XLS/XLSX): Not ideal for large-scale pipelines but great for sharing, reviewing, or doing quick exploratory analysis. Some data teams prefer it for manual annotation tasks.
- TXT and XML: Often used for raw text or annotated corpora, especially in natural language processing.
- Image or audio formats: For non-text data, you’re looking at JPEGs, PNGs, MP3s, WAVs, etc.
Real-world web data is rarely delivered in these neat formats. You’re more likely to find it buried in HTML, scattered across APIs, or locked behind login walls.
Access to clean, structured data from the start saves a ton of time. Especially when that data comes pre-organized in the format you need. Services like X are perfect for this, as you readily get structured, curated data in the format you need it in.
But where does data come from, to begin with?
| Want high-quality data at scale, just the way you want? Reach out to us. Data quality is the primary factor that determines how well your AI model works. With Grepsr, you don’t need to worry about creating your own scrapers, proxies, or getting blocked. Simply let us know what you want (and how), and we’ll give you clean, high-quality data at scale, just how you want it. Grepsr integrates with your systems and enables a seamless data pipeline for your AI. Happy training! |
Data Sources: Where the Data Actually Comes From
Before a model can learn anything useful, you need to give it the right data, and that starts with where you’re getting it from.
The source matters. It shapes what the model learns, how well it performs, and whether it ends up being helpful or just confidently wrong.
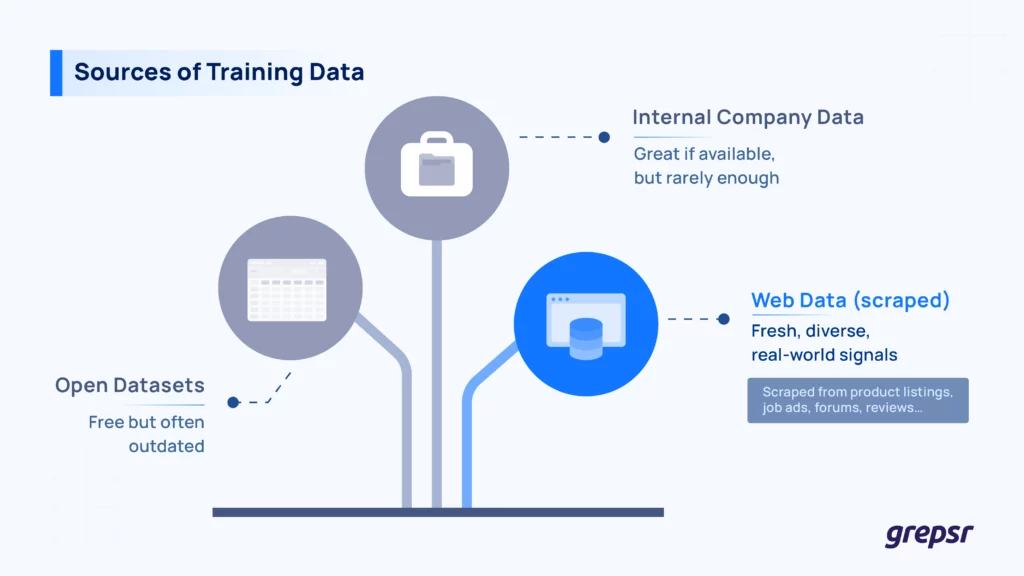
Some common places where training data comes from include
- Open datasets: There are plenty of freely available datasets, like CIFAR-10, Common Crawl, WikiText, etc. They’re great for benchmarking and research. But they’re often outdated or too broad to be useful in specific, real-world applications.
- Company-owned data. Internal logs, past transactions, support tickets; great if you have it. But most of it isn’t large or diverse enough to train complex models on its own.
- Web data. This is the big one. The web is full of fresh, high-signal content: product specs, job ads, real estate listings, news articles, discussion threads. It reflects how people write, search, shop, and think. But it’s not neatly packaged.
Web scraping is tricky. You run into rate limits, page structure changes, anti-bot measures, login walls.
Grepsr has built a web scraping service that handles all of that. Custom bots, anti-blocking systems, fast turnaround. You tell them what data you need, and they deliver it—structured, cleaned, and ready to use, in whatever format works for you (CSV, Excel, JSON).
And considering that data collection and prep still eats up around 80% of the time in AI projects, having a reliable source is a huge plus.

What Usable Data Looks Like
So let’s say you’ve got the data—scraped, structured, delivered in a neat JSON or CSV file. What now?

Even when it’s clean and well-formatted, not all data is automatically useful for training AI. Usability, in an AI context, means the data is not only clean, but also optimized for learning. That includes everything from structure and labeling to distribution and semantic richness.
Task-Relevance and alignment
Model performance starts with alignment. If you’re training a recommendation system, product metadata alone isn’t enough; you need user behavior logs, timestamps, and possibly sequence data.
For NLP, domain specificity matters: financial sentiment models trained on general Twitter data? Probably not ideal.
Usable data reflects the actual signal your model is expected to learn.
Annotation (when applicable)
For supervised tasks, ground truth labels are important. These could be binary flags, class categories, bounding boxes, sentiment scores, depending on the task. The quality of annotations has a direct impact on convergence speed and generalization.
Usable datasets either come pre-labeled or include enough structure to enable efficient annotation pipelines.
Contextual richness
High-quality data includes features with semantic weight. For instance, job titles with skills, product listings with specs and customer sentiment, or articles with publication time and source.
This context adds dimensionality, which helps models build more meaningful representations.
Distribution and newness
A model trained on skewed or outdated data is essentially overfitting to the past.
Usable data maintains a reasonable class distribution and reflects current behavior or trends.
With services like Grepsr, you’re getting access to web data that’s continuously updated, which makes it easier to avoid temporal drift and concept decay in production systems.
Data Or Nada
At the end of the day, models don’t train themselves. And they definitely don’t succeed on junk data. The real competitive edge is upstream; the quality, relevance, and usability of the data you feed it.
If you wanna skip the episode with raw web pages, rate limits, or patchy datasets, let Grepsr do the heavy lifting.
We’ll get you the data you need—clean, structured, and training-ready—so you can focus on building smarter systems, faster.































































































































































