


The early days of web scraping were simple: a few lines of code could pull everything you needed.
Today’s internet is armed with defenses and built on complex frameworks.
There are several web scraping challenges to bog you down.
Scrapers face everything from bot detection to complex site structures. Let’s talk about the biggest challenges in scraping and a simple way to scrape the web without limits—Grepsr.
But first…
A Quick Primer: What’s Web Scraping?
To recap, web scraping is the automatic collection of information from websites.
Technically, it starts with sending HTTP requests to a page and parsing the resulting HTML for useful data. Tools like BeautifulSoup, and browser automation frameworks like Selenium or Playwright make this easier, at least at first.
Web scraping is pretty much a given in price monitoring, lead generation, sentiment analysis, market intelligence, and more.
While the motive is straightforward, the execution is the opposite of that.
What are the Biggest Web Scraping Challenges?
Anyone who’s tried scraping beyond a few hundred pages knows that the challenge isn’t in writing the scrape, it’s keeping it running.
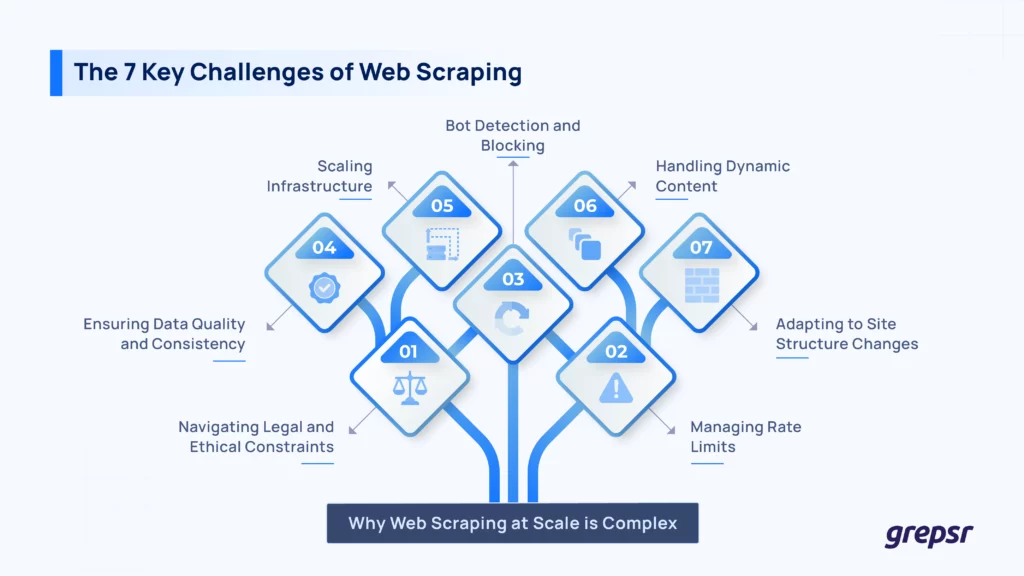
These are some of the biggest issues with web scraping and how serious scrapers handle them:
Challenge #1: Finding your way across bot detectors and blockers
Modern websites are pretty aggressive at blocking non-human visitors. Scraping bots are detected through an arsenal of techniques:
- CAPTCHAs (reCAPTCHA, hCaptcha, or FunCAPTCHA)
- Anti-Bot like Cloudflare Turnstile, Datadome, PerimeterX
- Browser fingerprinting by analyzing everything from HTTP headers to canvas and font rendering
- Behavioral analysis that checks for natural mouse movement, scrolling, and typing patterns
- TLS fingerprinting and IP reputation scoring to sniff out proxy use

Via Reddit
Even minute inconsistencies like a missing header here or a strange typing speed there give away a bot. To bypass these defenses, developers use a few tricks.
- They rotate residential or mobile proxies to mask IPs,
- Cycling user-agents and randomizing headers,
- Using browser fingerprinting.
- Running scripts inside headless browsers is also common,
- Some even opt for CAPTCHA-solving services (either through APIs or, believe it or not, real humans).
But these DIY methods come with heavy costs. Proxies and CAPTCHA solvers add up quickly. Headless browser fleets are resource-intensive. And detection systems keep changing all the time.
Here’s what a seemingly knowledgeable Redditor had to say on this:

Via Reddit
At a certain point, it’s more practical to use a service built to handle this complexity. Solutions like Grepsr invest in sophisticated bot behavior modeling and proxy management at scale, to deliver clean, structured data without the user needing to build and maintain an entire anti-detection stack themselves
Challenge #2: Handling dynamic content and JavaScript rendering
Static websites are increasingly rare. Most of the internet is saturated with dynamic content run by React, Angular, Vue.js, and the like. These sites load minimal HTML at first, then fetch the real data asynchronously through XHR or Fetch requests once the page is live.
The problem is that standard HTTP scraping tools only retrieve the initial page shell, missing out on all the data rendered client-side. If you’re scraping with Requests or BeautifulSoup, you’ll likely end up with a half-empty page.
There are two ways to deal with this:
- Browser automation: Tools like Playwright, Puppeteer, or Selenium can fully render JavaScript; scrapers interact with the page as a human would.
- API sniffing: Some developers reverse-engineer the AJAX calls being made behind the scenes and query those APIs directly and grab structured data without rendering a full page.
However, both approaches have tradeoffs. Headless browsers are slow and consume a lot of memory; you can’t scale them for high-volume scraping. On the other hand, relying on undocumented APIs is fragile; if the website updates its internal logic, your scraper would break overnight.
Challenge #3: Adjusting to constant changes to websites
Even though you overcome blockers and nail dynamic content, the truth is that scrapers are fragile. A tiny change to a site’s HTML, like a renamed CSS class or a reordered div, breaks scrapers that depend on specific selectors.
Scrapers usually identify the data by targeting HTML elements via CSS selectors or XPath expressions. When the page structure changes, even slightly, these pointers fail silently. And because these changes are subtle, it might take days (or longer) to realize your scraper is broken.
To reduce fragility, developers
- Use stronger selectors to target stable IDs, data-* attributes, or use relative XPath rather than brittle absolute paths.
- Implement fallback selectors in case a primary one fails.
- Build monitoring systems that flag anomalies like a sudden drop in data volume or unexpected field formats.
- Sometimes, devs layer in visual regression testing: comparing screenshots over time to detect major layout shifts (though it’s complex and heavy).
- Demo runs before the actual schedule or regular run to detect issue early
Even with all this, maintaining resilience is difficult. Others have agreed:

Via Reddit
Scraping-as-a-Service offerings like Grepsr are your best bet when structure changes become frequent (as they do with e-commerce or news sites).
Challenge #4: Managing rate limits and avoiding server overload
Even if your scraper is perfectly stealthy and your selectors are strong, you’ll likely be blocked if you send too many requests too quickly. Most websites have rate limits in place to protect their servers from abuse.
You’ll come across HTTP 429 (too many requests) or 503 errors if you exceed them, and maybe get IP-banned.
To get around this, you have to balance scraping speed with server tolerance. You could
- Honor robots.txt crawl-delay directives (more of a guideline than a rule),
- Build in adaptive delays: slowing down after errors,
- Distribute requests across a large pool of IP addresses, often from residential or mobile proxies, and
- Manage session persistence (cookies, authentication tokens) across multiple threads and proxies to avoid raising red flags.
All this demands careful queuing, concurrency control, and proxy health monitoring: a lot of moving parts.
Some scrapers build this infrastructure in-house while others turn to scraping platforms like Grepsr which already have session management, proxy rotation, and the like in their systems.

Challenge #5: Maintaining data quality, consistency, and structure
Ok, you’ve managed to collect the data you wanted. Great. But raw scraped data is messy, inconsistent, and unusable
Different pages format the same information differently. Fields would be missing, labeled inconsistently, or encoded weirdly. Prices will have different currency symbols, dates will be formatted differently depending on region, and special characters cause stupid encoding errors.
You need strong pipelines to handle this at scale. This involves writing parsing rules to extract and clean the data. Validation schemas with libraries like Pydantic also help with consistency. For example, ensuring a price field always contains a float instead of a random string.
You’ll also need normalization scripts for standardizing formats across dates, currencies, and text encodings.
These pipelines aren’t optional if you want reliable outputs, but they’re labor-intensive and warrant domain expertise.

Since Grepsr delivers pre-cleaned formats (like CSV, JSON, XML) with structured rows and columns, you can skip the messy post-processing phase and feed the data directly into models or databases.
Challenge #6: Scalability and infrastructure complexity
Scraping a handful of pages on a weekend project is one thing. Scaling up to millions of pages across hundreds of sites is another.
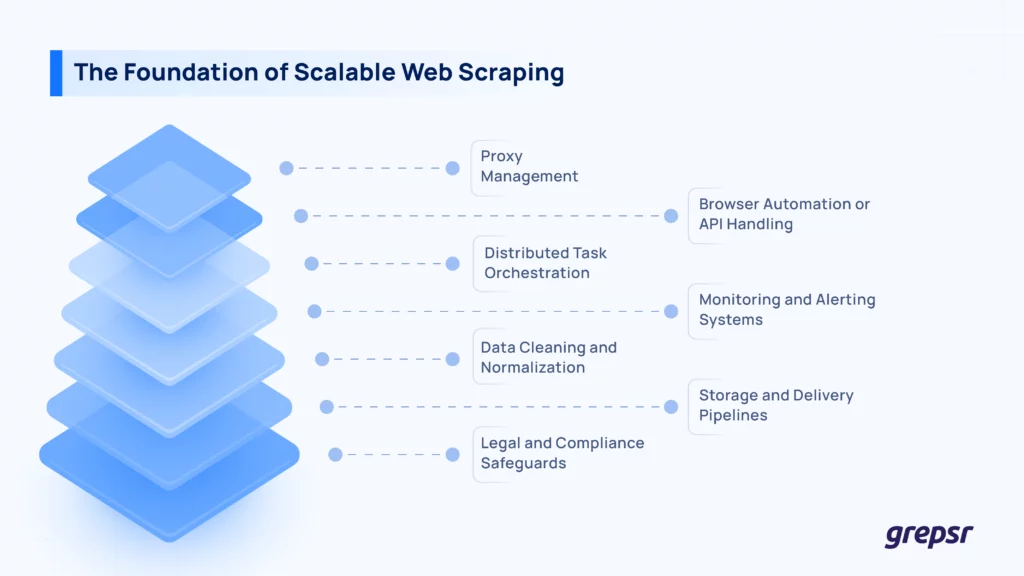
At scale, you’re kinda building a distributed system. You need to
- Manage proxy pools across multiple providers and types (datacenter, residential, mobile),
- Deploy and orchestrate scrapers using cloud servers or container technologies,
- Set up job queues to handle distributed task management without losing track of jobs,
- Store mountains of scraped data efficiently in databases, and
- Build monitoring dashboards to track scraper performance, error rates, etc.
And that’s before you even get to fault tolerance, auto-scaling, and cost optimization.
DIY-ing this setup is possible (big tech companies and serious data-driven startups do it all the time), but it would be a Goliath task. Plus, operational costs inflate quickly if infrastructure isn’t tuned.
Grepsr is perfect if you need reliable, high-volume data without these worries. Grepsr handles the distributed scraping, proxy management, dynamic scaling, data storage, and delivery, and frees your teams to focus on data usage instead.
Challenge #7: The legality and ethics of scraping what’s not yours
Web scraping lives in a legal and ethical grey area.
Some sites outright forbid scraping in their Terms of Service. Others allow it if you respect robots.txt directives, but the mere act of extracting data (even publicly visible data) sometimes triggers legal or enforcement actions.
International privacy laws like GDPR and CCPA make things even muddier, especially if scraped data includes personally identifiable information.
Ethical scraping practices include
- Only targeting publicly available data,
- Respecting robots.txt where possible,
- Implementing rate limits and polite crawling to avoid straining servers,
- Avoiding or anonymizing personal data wherever feasible,
- Consulting legal counsel before starting large-scale or sensitive scraping operations.
Even with these best practices, there’s no blanket guarantee.

Via Reddit
The law around scraping is shaky. Court cases, like the hiQ Labs v. LinkedIn one, have set important but sometimes conflicting precedents.
This is why legal compliance must be pushed into the scraping operation itself. Professional providers like Grepsr build their services around legally compliant scraping methodologies. They handle ToS restrictions and respect privacy laws.
That said, even with services like Grepsr, ultimate legal responsibility often falls on the end user.
Shoot Down All Web Scraping Challenges. Move to Grepsr
Every hour you waste fighting bot detection or fixing broken scrapers is an hour not spent using your data.
Grepsr gives you clean, reliable data in any format you want. It’s fast, structured, and ready for ingestion straight to your AI models, dashboards, and databases.



































































































































